RL for Intelligent Dosing
Why this is exciting
Consider a typical medical protocol, wherein a patient receives the maximum tolerable dose for chemotherapy. Shortly thereafter, tumor size decreases significantly. However, the patient soon undergoes relapse as tumors reappear – this time, untreatable. This exactly played out in a recent case study of melanoma, where the cancer cells learned to adapt to the drug. By killing only the subpopulation of cells susceptible to drugs, the (pre)resistant subpopulation was isolated and grew out of control. Unfortunately, this treatment protocol, and resulting behavior is widespread.
We hope to use AI to discover new dynamic dosing protocols that take into account this ability for cells to adapt to prior environmental pressures (e.g. presence of a drug). We hope that, in the not-too-distant future, AI can be leveraged to infer patient-specific protocols that result in better outcomes. Our work attempts to make a first step in this direction.
Physics → AI
- Long-range interactions. Previous work studying temporal drug dosing protocols failed to account for long-range temporal interactions (memory). We model this with a novel dynamical system confirmed by recent experimental evidence, establishing a new reinforcement learning environment.
- Control theory solution. RL recovers the known exact solution (in the case of zero memory) and discovers new dosing strategies, allowing control of cell populations even in the face non-Markovianity.
- Simplifying control. A bang-bang (“all or nothing”) policy is proved optimal in the proposed model, which greatly simplifies the control space from a continuous set to two discrete choices.
AI → Physics
- Framestacking. The simulated population dynamics environment is solved with model-free deep RL using frame-stacking to account for memory. This technique is borrowed from the seminal work on Atari.
- One policy. A generalist model is successfully trained, capable of solving the control problem under a wide range of biologically-plausible models, zero-shot (without re-training or finetuning).
- Medical plausibility. Most importantly, the derived RL policies are based only on a single easily-obtained population-level measurement (growth rates) rather than cell-level data (fractional sizes of resistant & susceptible populations), as required by prior work. This makes the policies more amenable to real-world deployment.
What the paper does
The paper studies a non-Markovian population control problem where the dynamics incorporate memory effects through a fractional derivative. The state evolution is governed by the following equation:
\[\dot x(t) = \int_0^t \frac{(t-\tau)^{\mu-2}}{|\Gamma(\mu-1)|} f(x(\tau), u(\tau)) d\tau\]where $\mu\in(0,1)$ is the memory strength parameter, $\Gamma$ is the gamma function, $f$ describes the linear dynamics of switching and growth rates, and $u(t)$ is the drug dosing control input. Note: decreasing values of $\mu$ correspond to stronger memory effects, and $\mu=1$ corresponds to the memoryless case.
1) Model of Adaptive Dynamics
The paper introduces a novel population model exhibiting phenotypic plasticity to study the control of memory-based systems, based on recent work discussing the role of memory in drug resistance. This model captures key features of adaptive dynamics observed in cancer and bacterial systems, such as the ability of cells to switch phenotypes in response to environmental pressures (e.g. drug presence), and the resulting long-range temporal interactions (memory) that arise from these dynamics.
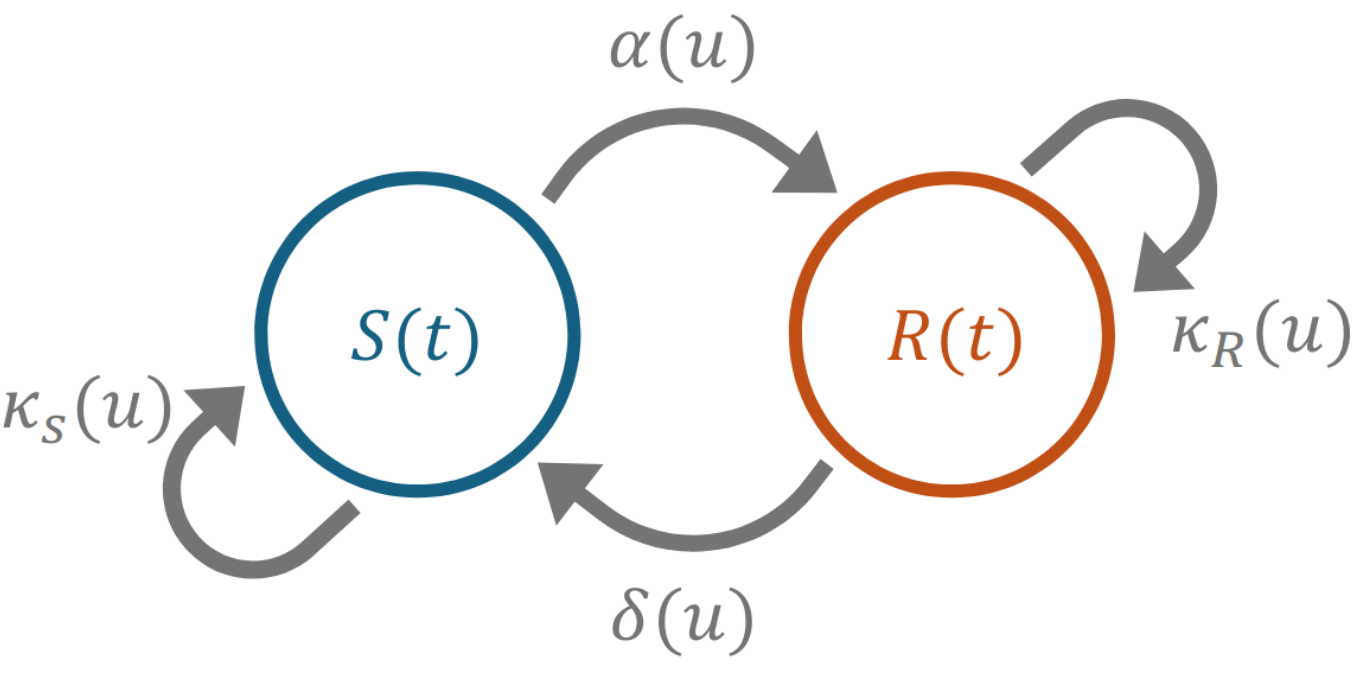
Figure 1: Depiction of the deterministic phenotypic switching model. The susceptible subpopulation S transitions to the resistant state R at a concentration-dependent rate, δ. Similarly, the resistant state switches back to a susceptible state at a rate α. The subpopulations each have a concentration-dependent growth or death rate, κ.
2) Leverage Control Theory
By proving that a bang-bang policy is optimal, we significantly simplify the action space for the RL agent. In fact, continuous action agents like PPO and SAC fail. DQN learns to quickly switch the drug on and off (in fact with increasing frequency over time), which is consistent with the optimal control solution. Continuous action algorithms must saturate their action spaces (which leads to vanishing gradients and ugly edge effects in the policy parameterization), which is likely the reason for their failure, despite extensive tuning and training. This highlights the importance of leveraging domain knowledge to inform the design of the RL problem, and the potential pitfalls of using more general algorithms without such insights.
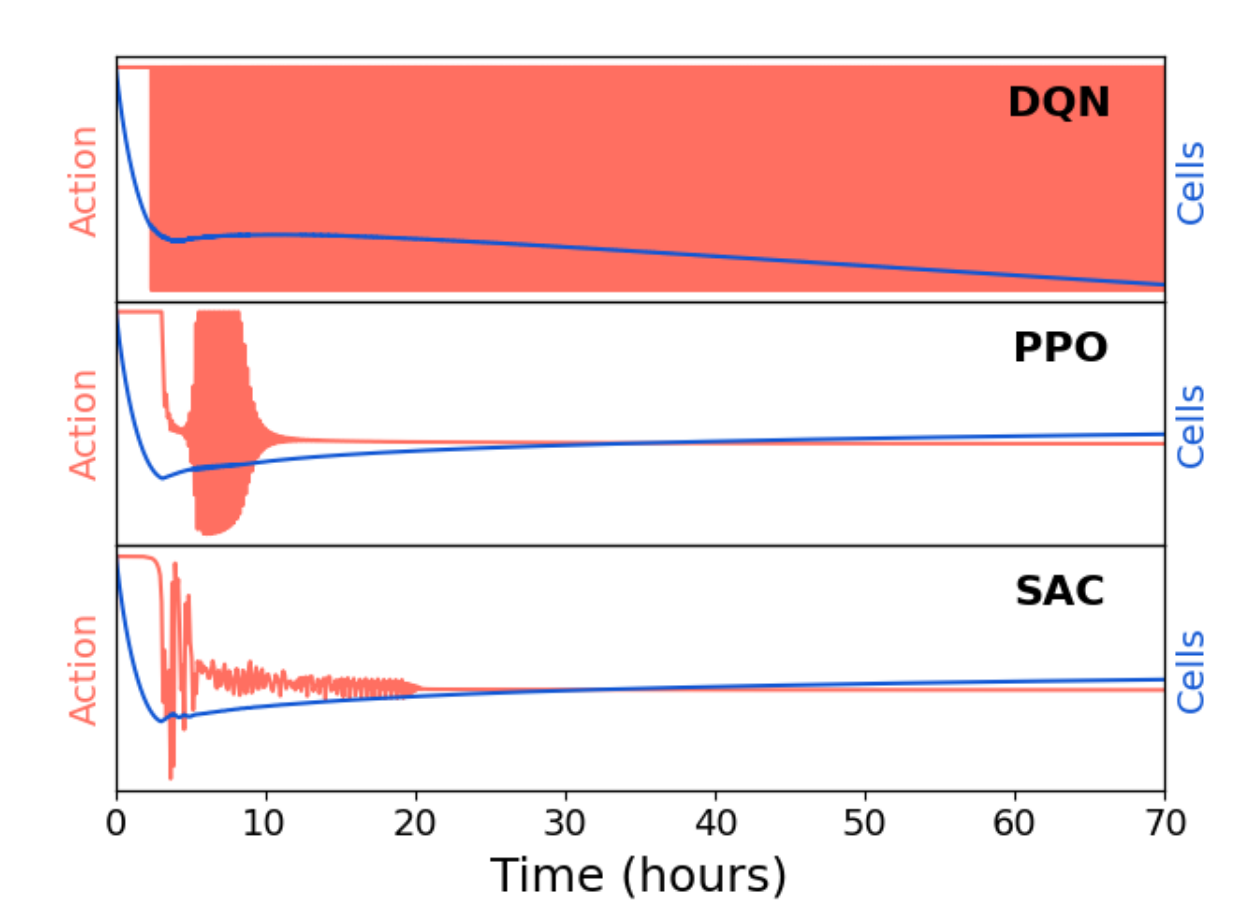
Figure 2: PPO and SAC fail to find a bang-bang control policy and have a lower performance than DQN; highlighting the need for discrete action algorithms, as informed by optimal control.
3) Prevent Resistance Buildup
RL agents discover treatment protocols which successfully prevent proliferation and resistance development in this model of cellular dynamics. A successful policy maintains a certain fraction of resistant cells. This value is implicitly learned by the agent. For the solvable model of no memory (which corresponds to $\mu=1.0$), the optimal fraction agrees with that learned by the agent. For increasing memory strength, the agent finds it is optimal to decrease the upper bound on the fraction of resistant cells, which is consistent with the intuition that memory effects make it more difficult to control the system, and thus require more aggressive control of the resistant subpopulation.
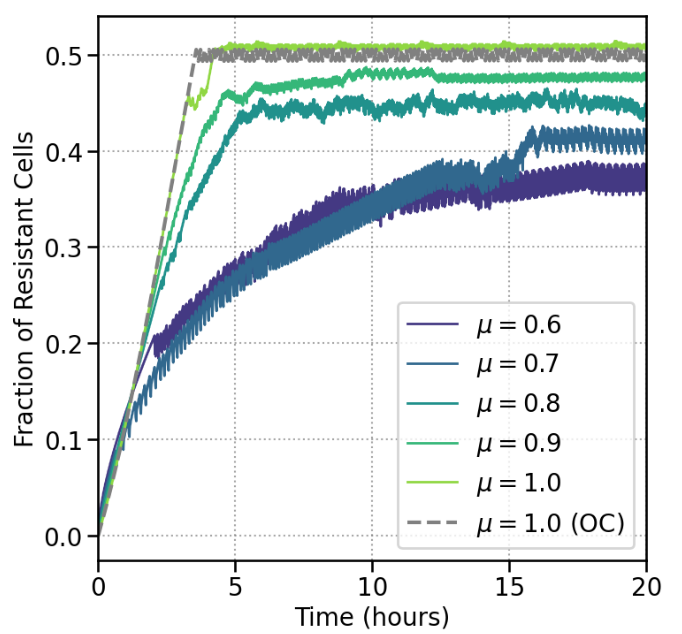
Figure 3: Effect of learned policy on resistant fraction. for different memory strengths. The RL agent finds (for distinct μ values) appropriate lower and upper bounds for the fraction of resistant cells. Maintaining the subpopulation in this range ensures the total cell population can be reduced.
A taste of the results
A single policy is trained to universally address all levels of memory. The resulting policy outperforms all other control schemes. Notice that a constant application of the drug is highly suboptimal (red line below), as the cells all become resistant, leading to exponential growth. We compare RL to the optimal solution for the memoryless case (green line), and a pulsing strategy (pink line) based on the resistant fraction (which is not clinically accessible, and must be determined ahead of time).
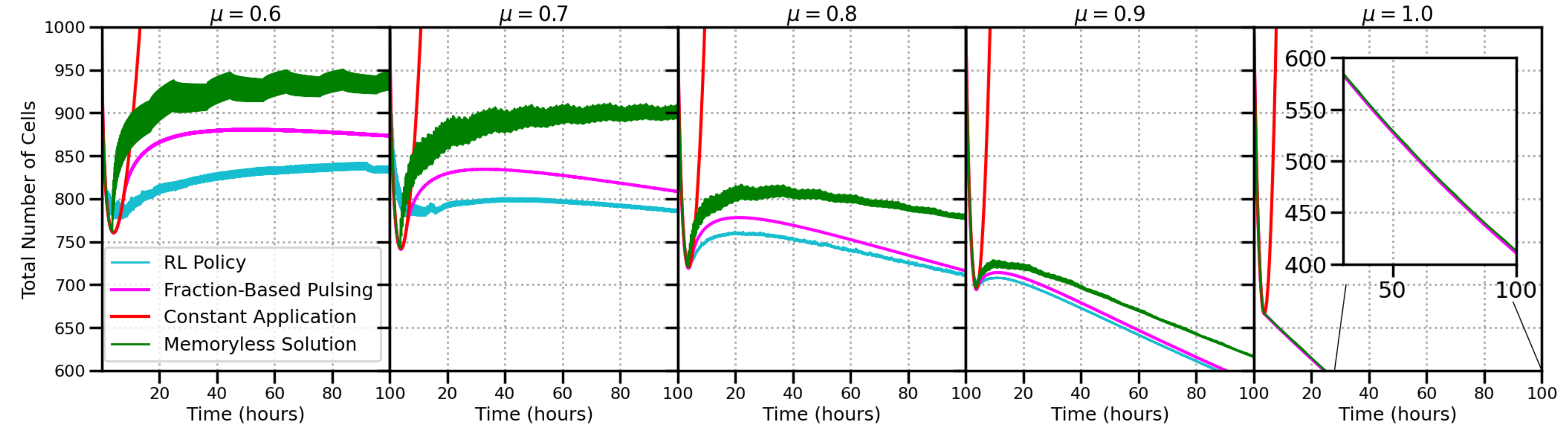 Figure 4: Performance comparison of constant drug application, solution for the memoryless case, resistant fraction-based pulsing technique, and policy learned by RL. For the fraction-based policy, an optimal lower and upper bound for resistant fractions are found numerically. The RL policy is capable of controlling the cell population better than any other scheme.
Figure 4: Performance comparison of constant drug application, solution for the memoryless case, resistant fraction-based pulsing technique, and policy learned by RL. For the fraction-based policy, an optimal lower and upper bound for resistant fractions are found numerically. The RL policy is capable of controlling the cell population better than any other scheme.
How it works (at a glance)
- Simulated dynamics Non-markovian dynamics are based on a fractional-order differential equation, which is integrated over time, with respect to the history of the agent’s actions. The reward function, the negative of the total growth rate (i.e. for both sub-populations), is used to encourage the agent to extinguish the entire population.
- Observations The environment is partially observable (agent does not receive information about the underlying state that governs the transition dynamics) and non-Markovian (the next state depends on the entire history). Though traditional RL approaches can struggle in this domain, we find that frame-stacking (giving the agent the past $K=5$ observations) is sufficient to learn a performant policy. Moreover, providing further context via memory-based policies (e.g. RNNs, LSTMs) did not further enhance the agent’s capabilities.
- Discrete actions Utilizing the proof of bang-bang optimality, we use only two actions, a minimum dose (zero) and maximal dose (normalized to unity in the chosen units). Though one may use continuous actions, we find that the corresponding algorithms (PPO, SAC) trained on this action space perform poorly, failing to converge to a useful policy.
- Robust training Upgrading from DQN to FQF, we find a single policy can universally address all levels of memory. The memory strength is not clinically accessible, making this an important contribution for downstream use. The resulting policy is also robust to measurement errors and shifts in biological parameters.
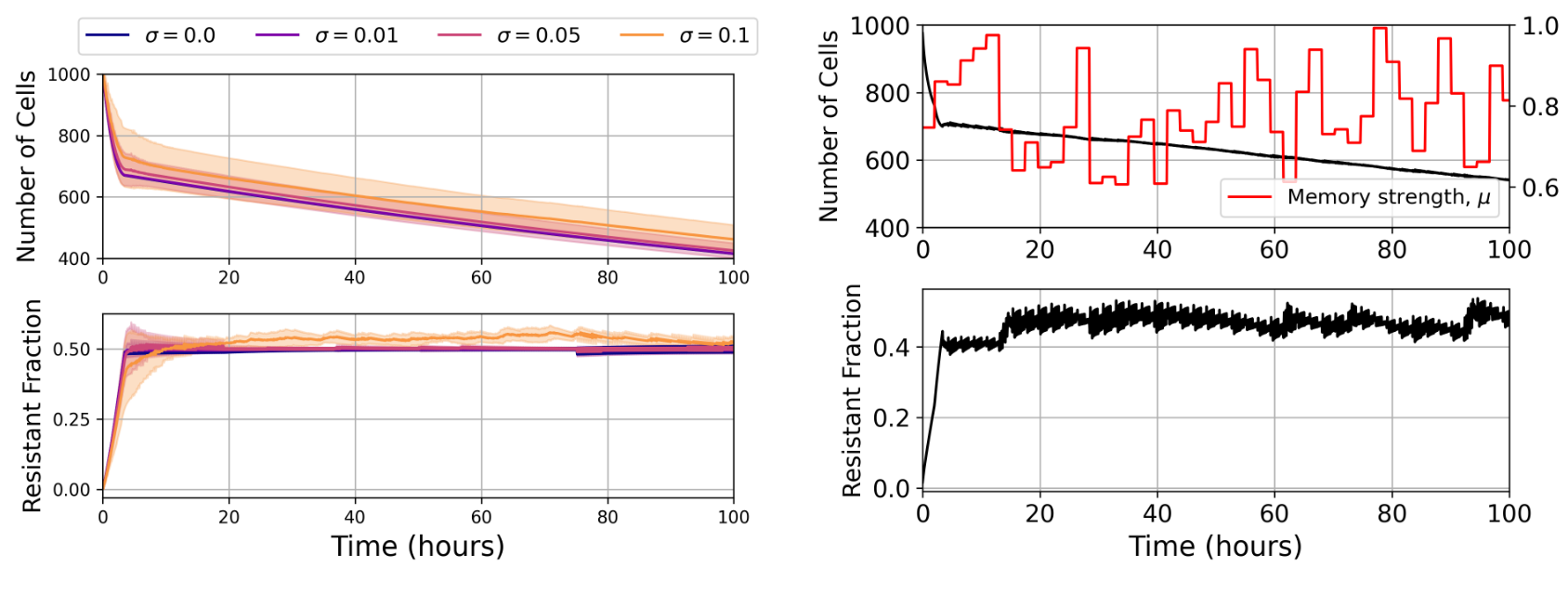 Figure 5: Left: Policy is robust to observation noise, as tested in a memoryless environment. To represent potential measurement errors in the clinical setting, noise is drawn from a normal distribution with standard deviation σ and added to each state before given to the agent. Despite large amounts of observation noise, the agent was able to drive population reduction and maintain a similar resistant fraction. Right: Learned policy is general and robust to changes in memory strength. Every 20 decision steps the memory strength is reset to a new value, drawn from a uniform distribution over the interval $[0.6, 1]$. Agent is able to quickly adapt to mitigate population growth in the new environment
Figure 5: Left: Policy is robust to observation noise, as tested in a memoryless environment. To represent potential measurement errors in the clinical setting, noise is drawn from a normal distribution with standard deviation σ and added to each state before given to the agent. Despite large amounts of observation noise, the agent was able to drive population reduction and maintain a similar resistant fraction. Right: Learned policy is general and robust to changes in memory strength. Every 20 decision steps the memory strength is reset to a new value, drawn from a uniform distribution over the interval $[0.6, 1]$. Agent is able to quickly adapt to mitigate population growth in the new environment
Limitations and outlook
- Clinical Constraints Rewards and optimality may be heavily influenced by factors such as patient well-being, cost of drug exposure, external interactions, pharmacokinetics (PK) and pharmacodynamics (PD), etc. Constraints on drug dosing (i.e. the maximum allowable frequency) are also a concern: our model finds that a policy should increase its frequency of drug pulsing over time. Overcoming these issues is important for eventual deployment.
- Sim-to-Real A hallmark problem of RL is the gap between simulation and the real-world. Our simulation is based on recent experiments but does not reflect the full complexities of the real-world. Since online learning is not an option in this domain, we must rely on more advanced models and offline RL techniques to learn from real-world data. This is a promising direction for future work.
- Next steps Future work will focus on bridging the gap for real-world applicability, in various dimensions: Novel computational approaches will be developed, e.g. new models that include other actions such as nutrient supply; offline RL solutions that leverage prior data; and policy evaluation on real-world experimental data.
Learn more
This work was supported in part by the National Science Foundation via the NSF AI Institute for Artificial Intelligence and Fundamental Interactions (IAIFI).